Core concepts¶
Data model¶
Terracotta is agnostic to the organization of your data, but you can cast almost any hierarchy into an API structure. The Terracotta data model is heavily inspired by the way we found ourselves organizing raster files on a hard drive:
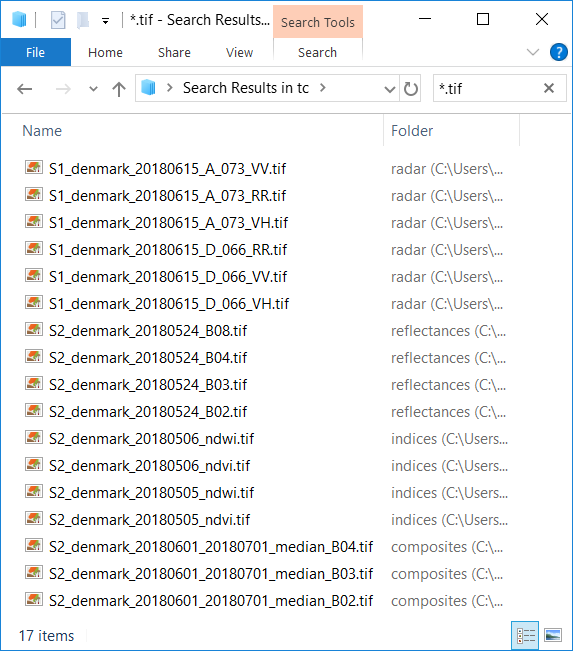
In this case, the raster images are fully categorized by their path, following the pattern
{type}/{sensor}_denmark_{date}_{...}_{band}.tif
The placeholders in curly brackets is what we call keys. You can see that this pattern of keys covers all raster files:
reflectances/S2_denmark_20180524_B03.tifhas type
reflectances, sensorS2, date20180524, and bandB03
radar/S1_denmark_20180615_A_073_VV.tifhas type
radar, sensorS1, date20180615, and bandVV
indices/S2_denmark_20180506_ndvi.tifhas type
indices, sensorS2, date20180506, and bandndvi(even though NDVI is not really a spectral band, it does fit the scheme well - sometimes organizing your data is about making compromises).
Keys can have any names and (string) values, and they do have a fixed
order. Keys are matched by alphanumeric values, and other characters
(-, _ or anything other than a letter or number) are treated as
value separators.
In Terracotta, the keys identifying a dataset immediately lead to an API representation. You can start a server for the example above via terracotta serve:
$ terracotta serve -r {type}/{sensor}_denmark_{date}_{}_{band}.tif
Then, the URL
localhost:5000/rgb/reflectances/20180524/preview.png?r=B04&g=B03&b=B02
gives you an RGB image composed of the raster files
reflectances/S2_denmark_20180524_{B04,B03,B02}.tif, and
localhost:5000/singleband/indices/20180506/ndvi/{z}/{x}/{y}.png
serves the file indices/S2_denmark_20180506_ndvi.tif as an XYZ tile
layer. You can also search for data; the query
localhost:5000/datasets?type=indices&band=ndvi
returns a JSON array of all known NDVI datasets.
Note
While keys in Terracotta are certainly inspired by file naming
conventions, they do not need to coincide with actual file names. You
are free to ingest a file called myraster.tif with the keys
('S2', '20180601', 'B04') should you wish to do so.
Architecture¶
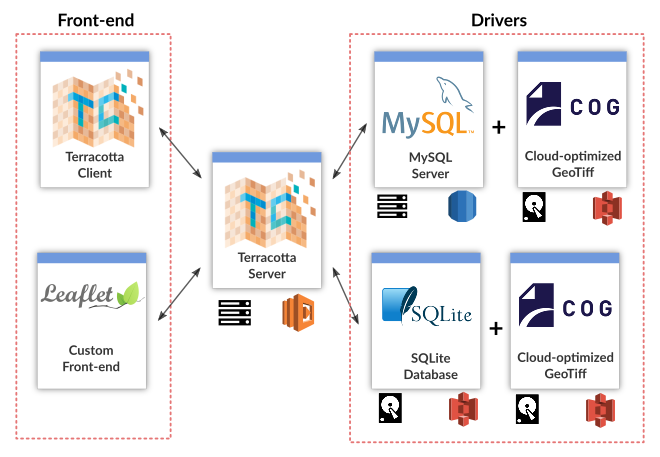
In Terracotta, all heavy lifting is done by a so-called driver. The driver specifies where and how Terracotta can find the raster data and metadata it requires to serve a dataset. Most drivers use a database to store metadata and rely on a file system to store raster data, but neither of those assumptions are enforced by the API.
Currently implemented drivers include:
SQLite + GeoTiff
Metadata is backed in an SQLite database, along with the paths to the (physical) raster files. This is the simplest driver, and is used by default in most applications. Both the SQLite database and the raster files may be stored in AWS S3 buckets.
MySQL + GeoTiff
Similar to the SQLite driver, but uses a centralized MySQL database to store metadata. This driver is an excellent candidate for deployments on cloud services, e.g. through AWS Aurora Serverless.
Why serverless?¶
We think that serverless architectures (specifically AWS Lambda) are a great fit for tile servers:
Many tile servers host highly specialized data that is only used sporadically. However, even a single user fires hundreds of concurrent requests. AWS Lambda makes it possible to keep costs low when things are slow while providing the capacity needed for peak times.
Concurrency is key to a good user experience, and much more important than single-tile loading times.
Serverless deployments are virtually maintenance-free and can stay online for years.
Limitations¶
Terracotta is light-weight and optimized for simplicity and flexibility. This has a few trade-offs:
The number of keys and their names are fixed for one Terracotta instance. You have to organize all of your data into the same structure - or deploy several instances of Terracotta.
Terracotta keys are always strings and carry no intrinsic meaning. You can search and filter available datasets through exact comparisons (e.g. by calling
/datasets?type=index&date=20180101), but more sophisticated operations have to take place in the frontend.You can only use the last key to compose RGB images (i.e., the last key must be
bandor similar).Since the names and semantics of the keys of a Terracotta deployment are flexible, there are no guarantees that two different Terracotta deployments have the same dataset API. However, all information is transparently available from the frontend, via the
/swagger.json,/apidoc, and/keysAPI endpoints.While Terracotta is pretty fast, we favor flexibility over raw speed. If sub-second response times are a hard requirement for you, Terracotta might not be the right tool for the job.
